
Galexie
Situation : catégoriser des élèves et des exercices.
Illustrations : Wikipedia.
| sont des étiquettes | sont des valeurs | |
|---|---|---|
| ne se suivent pas | nominales (nom, sexe, ...) |
de ratios (distance, durée, ...) |
| se suivent | ordinales (1er, 2ème, échelle de Likert, ...) |
d'intervalles (date, température, ...) |
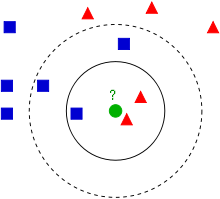 La méthode des k plus proches voisins catégorise les objets en fonction de leur proximité mutuelle, les considèrant alors comme similaires.
La méthode des k plus proches voisins catégorise les objets en fonction de leur proximité mutuelle, les considèrant alors comme similaires.
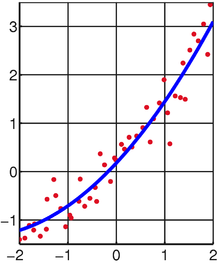 La méthode des moindres carrés ("Least Squares") prend en compte une série d'objets afin d'en déduire une fonction.
La méthode des moindres carrés ("Least Squares") prend en compte une série d'objets afin d'en déduire une fonction.
 Répartit des objets en plusieurs groupes (ou clusters). Est pris en compte la distance d'un objet par rapport à la moyenne des positions des objets du groupe.
Répartit des objets en plusieurs groupes (ou clusters). Est pris en compte la distance d'un objet par rapport à la moyenne des positions des objets du groupe.
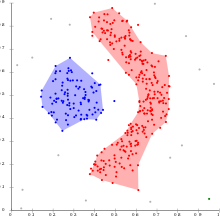 "Density-based spatial clustering of applications with noise" répartit les objets en plusieurs groupes (clusters) selon la distance les séparant, leur densité et un nombre minimum d'objets voisins pour y considérer l'un d'eux comme le centre.
"Density-based spatial clustering of applications with noise" répartit les objets en plusieurs groupes (clusters) selon la distance les séparant, leur densité et un nombre minimum d'objets voisins pour y considérer l'un d'eux comme le centre.
| K-NEAREST NEIGHBORS | NAIVE BAYES | LEAST SQUARES | A-PRIORI | K-MEANS CLUSTERING | DBSCAN CLUSTERING | ||
|---|---|---|---|---|---|---|---|
| échantillon | de ratios [[1, 3], [1, 4], [2, 4], [3, 1], [4, 1], [4, 2]] |
de ratios [[5, 1, 1], [1, 5, 1], [1, 1, 5]] |
ordinales [[60], [61], [62], [63], [65]] |
nominales [['alpha', 'beta', 'epsilon'], ['alpha', 'beta', 'theta'], ['alpha', 'beta', 'epsilon'], ['alpha', 'beta', 'theta']] |
de ratios [[1, 1], [8, 7], [1, 2], [7, 8], [2, 1], [8, 9]] |
de ratios [[1, 1], [8, 7], [1, 2], [7, 8], [2, 1], [8, 9]] |
|
| étiquettes | nominales ['a', 'a', 'a', 'b', 'b', 'b'] |
nominales ['a', 'b', 'c'] |
|||||
| valeurs | de ratios [3.1, 3.6, 3.8, 4, 4.1] |
||||||
| question | [3, 2] | [3, 1, 1] | [64] | ['alpha','theta'] | epsilon = 2, minSamples = 3 | ||
| réponse | b | a | 4.06 | beta | [0=>[[1, 1], ...], 1=>[[8, 7], ...]] | [0=>[[1, 1], ...], 1=>[[8, 7], ...]] |
Lortet, A. (2019). Apprentissage automatique [Application en ligne]. Repéré à https://ml.galexie.com
Les algorithmes utilisés proviennent de la bibliothèque PHP-ML d'Arkadiusz Kondas.Kondas, A. (2016). Fresh approach to Machine Learning in PHP. Repéré à https://github.com/php-ai/php-ml